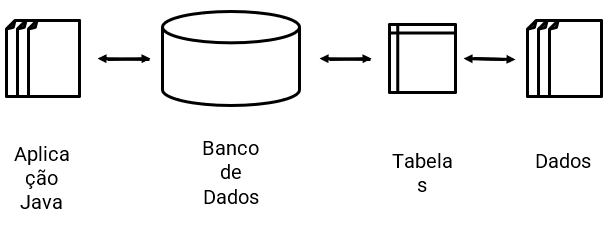
Àmedida que uma aplicação exige o registro e consulta de um grande volume de informações, apenas o uso de arquivos se torna algo complexo e custoso. Como alternativa, existem os banco de dados, ou seja, coleções organizadas de dados estruturados. Essa organização e estrutura dependem da escolha da pessoa programadora. Atualmente estão disponíveis no mercado dois tipos de bancos de dados: relacional e não relacional.
O modelo relacional é baseado na proposta de E.F. Codd de 1970, uma forma intuitiva e direta de representar os dados em tabelas. Neste modelo, cada linha da tabela é um registro com uma identificação única chamada de chave primária. As colunas contêm os atributos dos dados e, cada registro geralmente tem um valor para cada atributo, facilitando o estabelecimento das relações entre dados. Existem diversos sistemas diferentes para gerenciar bancos de dados relacionais. Esses sistemas são conhecidos como sistemas de gerenciamento de bancos de dados relacionais (SGBDR). O mais popular entre eles é o MySQL, mas também há outras opções como: Oracle database, Microsoft SQL Server, e Postgres. A grande maioria dos SGBDRs oferecem a opção de usar a Structured Query Language (SQL) para consulta e manutenção dos bancos de dados.
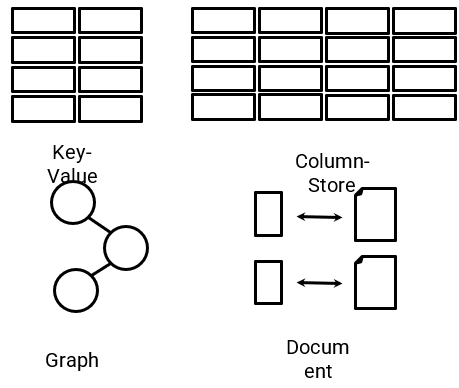
As bases de dados não relacionais são caracterizadas exatamente pelo o que o nome já diz, ou seja, por não seguir o modelo relacional dos sistemas de gerenciamento tradicionais. Essa categoria também é conhecida por NoSQL. Os mais populares do mercado são: MongoDB, DocumentDB, Cassandra, Couchbase, HBase, Redis, e Neo4j. Estes bancos de dados são geralmente agrupados em quatro categorias: Key-value stores, Graph stores, Column stores, e Document stores.
As bases de dados não relacionais são caracterizadas exatamente pelo o que o nome já diz, ou seja, por não seguir o modelo relacional dos sistemas de gerenciamento tradicionais. Essa categoria também é conhecida por NoSQL. Os mais populares do mercado são: MongoDB, DocumentDB, Cassandra, Couchbase, HBase, Redis, e Neo4j. Estes bancos de dados são geralmente agrupados em quatro categorias: Key-value stores, Graph stores, Column stores, e Document stores.
O processo de criação de um banco de dados depende muito do sistema a ser utilizado. Na maior parte deles, basta entrar no site oficial e utilizar o instalador oficial. Feito isso, um usuário administrador será criado (com a senha que o usuário inserir) e, através da linha de comando no terminal ou por meio de uma ferramenta visual, o usuário já tem a possibilidade de criar bancos, tabelas, inserir dados, consultar dados e assim por diante; seja em um banco relacional ou não.
O que é o JDBC?
JDBC meios Java Data Base Conectivity, que é uma API Java padrão para conectividade independente do banco de dados entre a linguagem de programação Java e uma vasta gama de bases de dados.
A biblioteca JDBC inclui APIs para cada uma das tarefas mencionadas abaixo, geralmente associadas ao uso do banco de dados.
Fundamentalmente, o JDBC é uma especificação que fornece um conjunto completo de interfaces que permite acesso portátil a um banco de dados subjacente. Java pode ser usado para escrever diferentes tipos de executáveis, como -