
Consultas envolvendo três ou mais tabelas funcionam da mesma forma que consultas com duas tabelas. O resultado da consulta consiste na seleção de linhas do produto cartesiano de todas as tabelas envolvidas.
Para uma consulta envolvendo 3 tabelas com 1.000, 5.000 e 10.000 linhas cada, o produto cartesiano origina uma tabela com 500 bilhões de linhas! Certamente os SGBDS não fazem o produto cartesiano antes da seleção das linhas. Eles utilizam algoritmos bastante sofisticados para simultaneamente combinar e selecionar de linhas. De qualquer forma, o desempenho de uma junção depende da quantidade de tabelas envolvidas, do tamanho destas tabelas e das condições impostas nas cláusulas WHERE e ON. Considere o diagrama ER a seguir:
As entidades FORNECEDOR, PECA e PRODUTO e os relacionamentos FORNECE e UTILIZA são mapeados em 5 tabelas. Os atributos não foram mostrados. Os comandos de criação e inserção de registros estão no material de apoio.
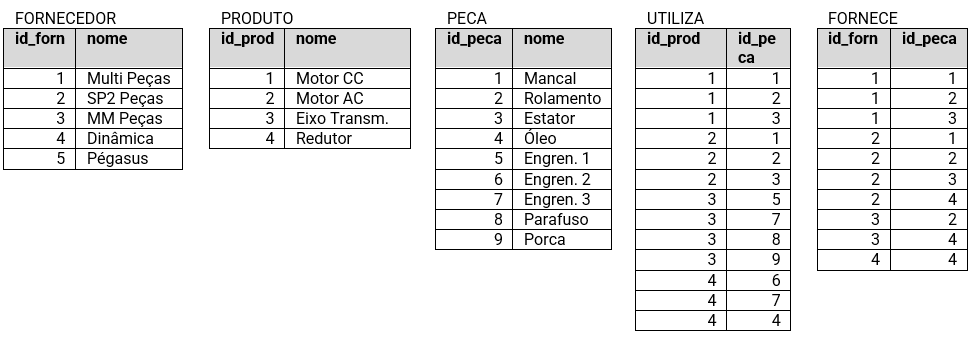
A relação de todos os fornecedores e peças que fornecem:
SELECT F.nome AS FORNEC, P.nome AS PECA
FROM FORNECEDOR AS F LEFT OUTER JOIN FORNECE AS R ON F.fornec_id = R. fornec_id
LEFT OUTER JOIN PECA AS P ON P.peca_id = R.peca_id;
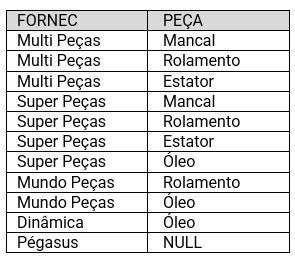
Observe que foram feitos dois LEFT OUTER JOIN em sequência. Primeiramente, o mais à esquerda é executado e seu resultado e colocado em uma tabela temporária (virtual). Em seguida, o outro é executado entre a tabela temporária e PECA. Pode-se colocar em sequência quantas junções forem necessárias. A execução sempre será da esquerda para a direita e os resultados intermediários são colocados em tabelas temporárias. Na realidade, a consulta acima pode ser feita com um RIGHT OUTER JOIN e um INNER JOIN (por quê? verifique!):
SELECT F.nome AS FORNEC, P.nome AS PECA
FROM PECA AS P INNER JOIN FORNECE AS R ON F.PECA_id = R. fornec_id
RIGHT OUTER JOIN FORNECEDOR AS F ON F.FORNEC_id = R.peca_id;
As operações de junção realizam sempre a seleção de linhas a partir do produto cartesiano das tabelas envolvidas. Estas tabelas possuem, na grande maioria das situações, estruturas distintas. O operador UNION permite que os resultados de duas ou mais consultas (SELECT) sejam unidas em uma só tabela. Algumas restrições: o número de colunas de todas as consultas envolvidas deve ser o mesmo; os tipos das colunas correspondentes em todas as consultas devem ser compatíveis.

UNION retira os registros duplicados por padrão, sem que seja necessário incluir o modificador DISTINCT. Para forçar a inclusão dos registros duplicados, o qualificador ALL deve ser usado. Um cuidado a ser tomado: o primeiro UNION [DISTINCT] que surgir, faz com que todos os registros duplicados até aquele momento sejam excluídos. Considere as tabelas a seguir:
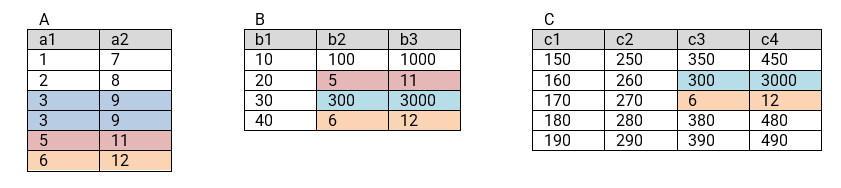

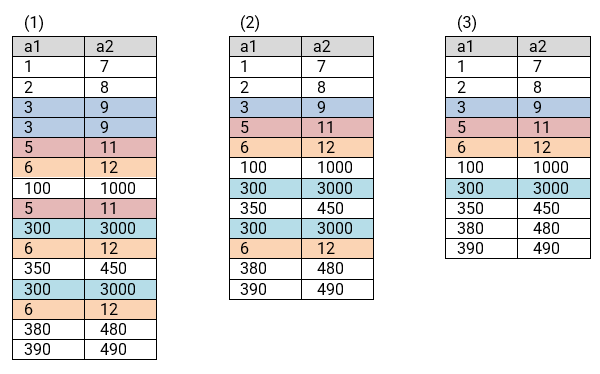
O operador INTERSECT faz o “oposto” do operador UNION: retorna as linhas que são comuns às consultas envolvidas. Embora alguns dialetos suportem o modificador ALL, o seu comportamento pode variar. Por conta disto, o funcionamento do INTERSECT será apresentado apenas com o modificador DISTINCT, que é o seu padrão.